Ensembl VEP plugins 的使用方法(Alphamissense、dbNSFP 等)
前言
以下是相关的官网链接,如果想要得到除本文内容以外更全面深入的了解,建议跳转相关链接进行查阅:
VEP plugins documentation:
https://grch37.ensembl.org/info/docs/tools/vep/script/vep_plugins.html
VEP install documentation:
https://grch37.ensembl.org/info/docs/tools/vep/script/vep_download.html
正文
安装 VEP
此处强烈建议使用 Docker 或者 Singularity 直接拉取 VEP 镜像进行分析,因为在 VEP image 中已经内置好所有的 plugin,无需自己手动下载。
考虑到 Docker 对权限的要求更高,因此这里以普适性更强的 Singularity 为例(Docker 用户有需求可通过文章开头链接前往官网进行参考):
1 | 拉取 VEP image |
之后就可以通过 singularity 运行 VEP:
1 | singularity exec vep.sif vep --help |
直接安装的方法:
1 | git clone https://github.com/Ensembl/ensembl-vep.git |
INSTALL.pl 可以通过指定一系列参数来进行自定义安装,这里介绍其中主要需要注意的几个:
--CACHE_VERSION选择特定的 Ensembl 版本,目前最新为 112,请根据自己正在使用的注释版本确定。--CACHEDIR下载数据库的存储路径,默认为$HOME/.vep,可自行修改。--PLUGINS指定下载的插件(plugins),通过逗号分隔。也可通过--PLUGINS all使其下载全部插件。
由于 INSTALL.pl 需要一定的依赖项,因此遇到安装报错时可前往其 documentation 查看是否存在依赖项缺失,此外 API 和数据库版本不同时可能存在兼容问题。但目前我使用最新版本的 VEP 进行旧版本数据库的注释是不存在任何问题的。
下载数据库
通过 INSTALL.pl 安装的另一个弊端就是可能下载速度非常慢,因此这里介绍一个自行安装数据库的方法,对于使用 singularity 或者已经配置好 vep 的情况,可以使用以下命令:
1 | mkdir vep_data |
使用其他版本时,可将上述网址中的 112 替换为其他版本号例如 110 等。
之后在运行 vep 时可以通过 --cache_version 指定需要使用的版本号。
下载 plugins 需要的文件
这里仅介绍 AlphaMissense 和 dbNSFP 两个插件的数据库构建方法,原因如下:
- AlphaMissense 对于非同义突变的影响预测具有目前最先进的性能。但由于其开发团队仅提供了 GENCODE V33(对应 Ensembl V98),因此很多更新版本注释中的突变可能没法找到其对应的 AlphaMissense score。且其 github 上仅提供模型架构而未提供训练后的权重信息,因此无法自行预测。但其结果依然是极具参考价值的。
- dbNSFP 是一个集成数据库,里面包含了众多 Variant Effect Predictor 的结果,包括但不限于 CADD、LINSIGHT、ESM1b、EVE、AlphaMissense 等各种 score,安装了该插件的效果等同于安装许多其他插件,从效率上讲极具价值。如果选择安装该数据库则可以考虑跳过 AlphaMissense,注意该数据库文件较大请注意剩余存储。

一些需要注意的事项:
- 插件下载好不代表可以直接使用,因为它需要基于对应数据库才能运行。
- AlphaMissense 是 vep 112 版本新发布的插件,不清楚旧版本 API 是否与其兼容。
- dbNSFP 中仅包含非同义突变的注释信息,因此其仅会对那些存在 missense_variant 的位点进行注释。如果你还需要统计同义突变或者内含子突变的 score(例如 CADD 等软件包含其他类型突变的影响),那么使用 dbNSFP 可能不是最好的选择。
- dbNSFP 本身使用的注释版本可能与 VEP 具有冲突,这可能导致相关的预测结果在不同版本间存在冲突,详见 issue#626。
- 建议将所有数据库下载到同一目录下的不同子目录中,方便进行管理和可能需要的路径绑定。
AlphaMissense 安装
更多细节见:https://grch37.ensembl.org/info/docs/tools/vep/script/vep_plugins.html#alphamissense
请自行选择安装该数据库的路径 [PATH],然后运行以下命令:
1 | cd [PATH] |
此后对数据库进行构建,以使用 hg38 版本为例:
1 | tabix -s 1 -b 2 -e 2 -f -S 1 AlphaMissense_hg38.tsv.gz |
建立好索引后,在运行 VEP 时可以通过以下命令进行 Alphamissense score 注释:
1 | singularity exec /path/to/vep.sif -i variations.vcf --plugin AlphaMissense,file=/full/path/to/AlphaMissense_hg38.tsv.gz |
将 vep.sif 和 AlphaMissense_hg38.tsv.gz 的路径替换为自己的路径(详细运行示例可见下文)。
dbNSFP 安装
更多细节见:https://grch37.ensembl.org/info/docs/tools/vep/script/vep_plugins.html#dbnsfp
dbNSFP 每个版本分为 a c 两个类型,其中 a 适用于 academic use,c 适用于 commercial use。后者中不包含以下 effect score:
Polyphen2, VEST, REVEL, ClinPred, CADD, LINSIGHT, GenoCanyon
以下部分以 a 类型为例,该文章编写时 dbNSFP 的最新版本为 v4.8,若有变动请见其 documentation 页面。
请自行选择安装该数据库的路径 [PATH],然后运行以下命令:
1 | cd [PATH] |
下载后,通过以下命令进行数据库的构建:
1 | version=4.8a |
通过以下命令查看 dbNSFP 可以进行哪些 score 的注释:
1 | cat h | tr '\t' '\n' |
以上命令会打印出所有可以进行注释的列,通过在参数中指定这些列进行相应的注释,以 AlphaMissense 为例:
1 | cat h | tr '\t' '\n' | grep AlphaMissense |
在运行 VEP 时可以通过以下命令进行 Alphamissense score 注释:
1 | singularity exec /path/to/vep.sif -i variations.vcf --plugin dbNSFP,file=/path/to/dbNSFP${version}_grch38.gz,AlphaMissense_score |
如果要进行其他注释,则将 AlphaMissense_score 替换为对应的列名(即文件 h 中包含的那些名称)。如果要使用所有列,则指定 ALL 即可。
将 vep.sif 和 dbNSFP${version}_grch38.gz 的路径替换为自己的路径。
进行注释
以下是一个 dbNSFP 注释的示例:
1 | singularity exec -B /path/to/database:/path/to/database /path/to/vep.sif \ |
注意事项:
-B:该参数用于将目录挂载到 singularity 中,不是必选项。但是如果在运行中,各个插件文件的路径指定正确却依然返回找不到文件时,则需要通过 -B 将插件文件的目录挂载到 singularity 容器中进行访问。比如如果 dbNSFP 的目录在/database/dbNSFP中,则可以通过-B /database:/database将其目录挂载到容器的相同位置上,从而进行访问。- 将
/path/to/vep.sif//path/to/vep_data/[input vcf]/[output vcf]更改为自己的实际路径。 [version]指定下载的注释版本,如112。- dbNSFP 插件中的文件路径改为自己的实际路径。
- 要指定更多 dbNSFP 的列,只需要通过逗号作为分隔符添加即可。
或者你仅想进行 AlphaMissense 的注释:
1 | singularity exec -B /path/to/database:/path/to/database /path/to/vep.sif \ |
请根据自己的实际需求选择 hg38 或 hg19 版本。
多进程并行
不难察觉到,VEP 的运行速度是非常慢的,如果想对基因组的所有 variants 进行注释可能需要花费大量的时间,因此可以通过以下几种方法降低所需时间:
- 仅选择特定区域的 variants,例如只取出那些落在 CDS 区域的 variants 等。
- 通过多进程进行并行注释。
关于如何选择仅在 CDS 区域的 variants 可见博客另一篇文章,这里仅提如何实现多进程并行。
首先,假设所有 variants 都在同一个文件里,那么一个简单的方法是将其拆分为不同染色体的 variants,然后对每一条染色体的 variants 进行并行注释:
1 | vcffile="example.vcf" # 请将该处的 vcf 替换为真实的 vcf 文件名称 |
拆分步骤如上所示,并行请根据实际情况决定方案,例如通过 slurm 调度系统或者 parallel 命令等实现。此处以 parallel 为例:
1 | ls ./subvcf/*.vcf | parallel -j [num] \ |
请将 -j 后的 [num] 替换为希望的并行作业数,最终的注释 vcf 文件将在 subvcf 中以 .anno.vcf 结尾。
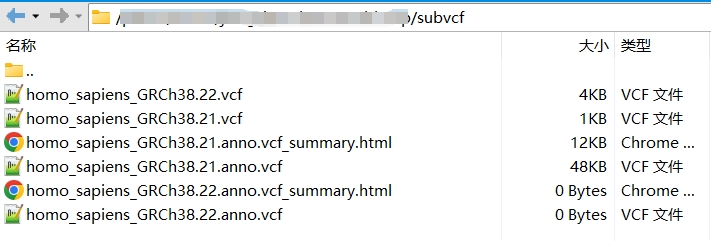
以上方案依然存在两个问题:
①、不同染色体上的 variants 数量差异很大。
②、这样仅能做到最高同时并行 染色体数 个任务。
因此,也可以通过将文件拆分为 variants 数量相等的若干个文件进行并行,以下是一个示例:
1 | vcffile="example.vcf" |
以上命令将把文件分为拆分为 10 个子 vcf 文件,并行的方法同之前所述。如果需要拆分为更多的子文件以设置更高的并行数量,仅需调整 num_splits 即可。

注释结果解释
注释后,header 中会出现相应的说明字段,以 AlphaMissence 注释为例:
1 | ##INFO=<ID=CSQ,Number=.,Type=String,Description="Consequence annotations from Ensembl VEP. Format: Allele|Consequence|IMPACT|SYMBOL|Gene|Feature_type|Feature|BIOTYPE|EXON|INTRON|HGVSc|HGVSp|cDNA_position|CDS_position|Protein_position|Amino_acids|Codons|Existing_variation|DISTANCE|STRAND|FLAGS|SYMBOL_SOURCE|HGNC_ID|am_class|am_pathogenicity"> |
这里 INFO 中多出的 CSQ 为 Ensembl VEP 的注释结果,其中以 | 分隔所有注释信息,相应位置上对应的注释说明可见 header 说明。此外:
- 一个 variant 可能落在多个转录本中,因此对应的
CSQ会出现多条结果(以,分隔)。 - 也有可能该 variant 并不在某个 score 的注释区域内(例如 AlphaMissense 仅注释非同义突变),此时对应位置将为空。
后记
之前在 esm1b 的文章里看到他们用的就是 dbNSFP 来评估各个 VEP method 的表现,想一想先前我还傻楞地去一个一个下载,不禁感慨世界上有很多节省时间的方式,只是需要多花些时间、多长点见识才能了解到。
也希望这篇文章能帮其他人少走点弯路。