
fasterq-dump 下载 SRA 文件时报错的解决方法(err cmn_iter)
正文
这几天下载 SRA,遇到的错误有:
fasterq-dump.3.1.0 err: cmn_iter.c cmn_read_uint8_arrayfasterq-dump.3.1.0 err: cmn_iter.c cmn_read_String
以前使用 fasterq-dump 时只是偶然出现这些问题,重新下载也都能解决,但最近有些 SRA 一直下载失败,经过调查发现这种错误在大文件下载时出现异常频繁,且多次下载并没法有效解决问题,因此需要一个替代的方法。
解决方案
Prefetch
由于 fasterq-dump 直接通过 HTTP 下载得到 fastq 文件,该过程很可能由于一些问题中断从而导致下载失败。因此可以通过更稳定的 prefetch 先得到 sra 文件,再通过 fasterq-dump 提取 fastq 文件。
fasterq-dump fetches SRR on the fly via HTTP and there could be fatal errors during the transfer.
prefetch eliminates transfer problems.
具体操作:
1 | prefetch --max-size 100000000 [SRR id] |
使用 prefetch 下载的好处有两点:
- sra 文件占用的空间较小,因此下载速度更快。
- 下载如果因为某种原因中断,仍可以通过相同的命令进行断点重连。
以下是一个使用 slurm 调度系统进行批量下载和读取的示例,没有调度系统的朋友也可以直接参考命令进行多下载任务并行:
1 |
|
其中 download.list 为一行一个 SRR id 的文件。
1 |
|
这里使用 .sra* 作为后缀的原因是有时下载的 sra 文件其尾缀可能为 .sralite,具体差别可见 SRA Data Formats。
若想加速提取过程,可以根据自身情况调整并行数量和 fasterq-dump 使用的线程数量。以上方法经实测非常稳定,对于大文件而言也不会出现报错。
ascp
有时 prefetch 下载速度极缓慢,因此选择速度更快很多的 ascp 也是很好的替代方案。
conda 下载:
1 | 有 mamba 则用 mamba |
在 ENA Browser 搜索对应的 Accession Number,
勾选 fastq_aspera 后下载 TSV:
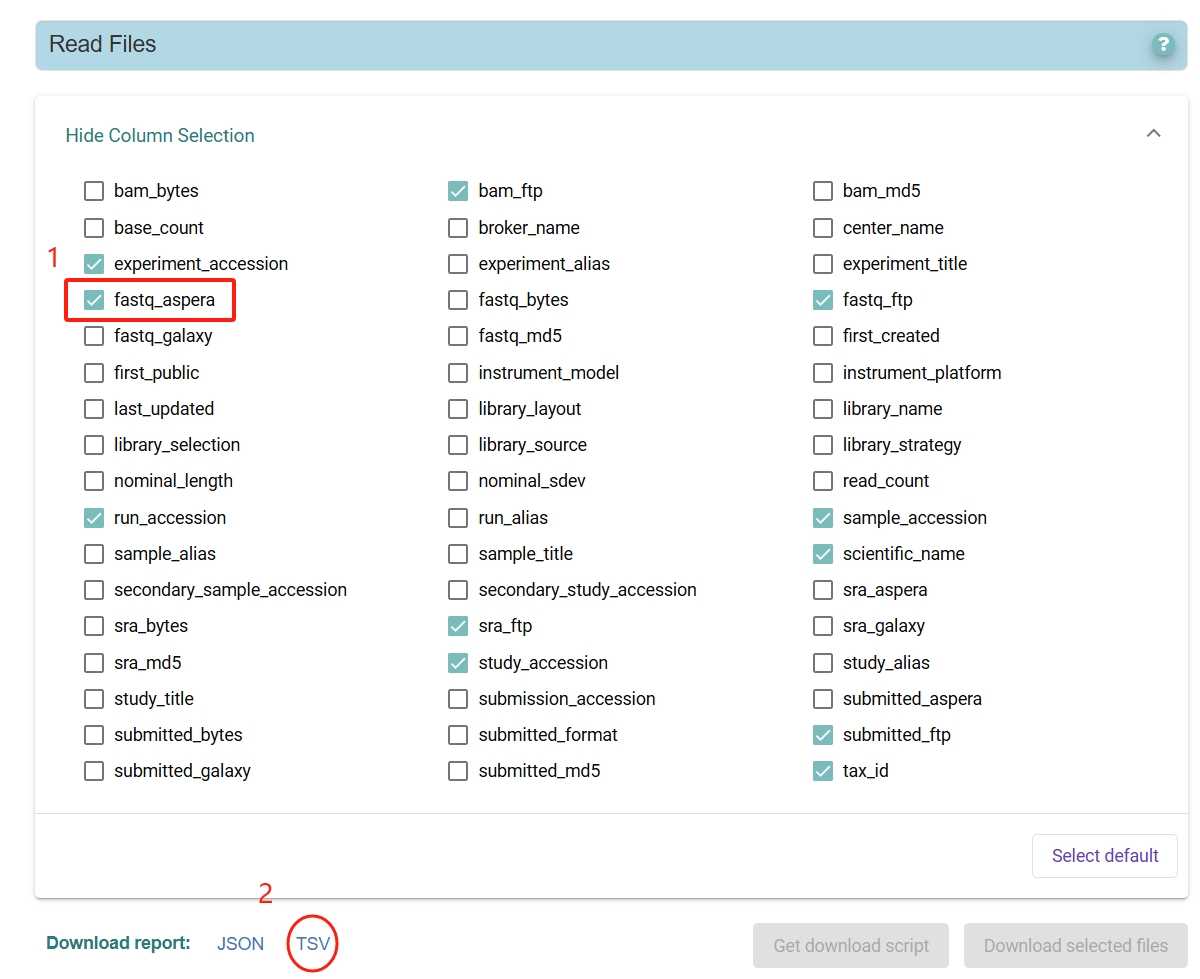
根据 fastq_ftp 列,制成以下类似文件:
1 | /vol1/fastq/ERR418/003/ERR4181783/ERR4181783_1.fastq.gz |
假设其命名为 download.list,使用以下命令下载:
1 | ascp -QT -k 1 -l 100m -P33001 -i /path/to/asperaweb_id_dsa.openssh --mode recv --user era-fasp --host fasp.sra.ebi.ac.uk --file-list ./download.list [output path] |
参数详解:
-Q:启用较少详细信息的输出模式(quiet mode)。-T:启用文件时间戳保留。文件传输完成后,目标文件的时间戳将与源文件相同。-k 1:断点续传。-l 100m:限制传输速率,最大传输速率为 100 Mbps。-P 33001:用于连接的端口号,33001是 Aspera 使用的默认端口号。-i /path/to/asperaweb_id_dsa.openssh:指定私钥文件的路径,用于身份验证。位于安装 ascp 的环境目录中的 etc 下。
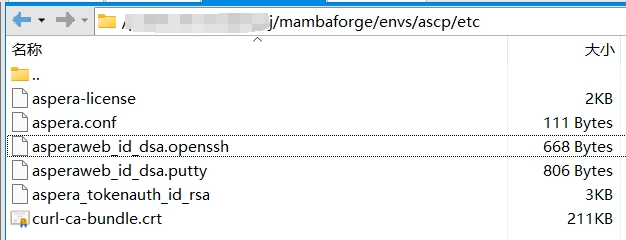
--mode recv:指定传输模式。recv表示接收文件(下载)。--user era-fasp:指定连接使用的用户名。--host fasp.sra.ebi.ac.uk:指定连接的主机名或 IP 地址。--file-list ./download.list:指定包含待传输文件列表的文件。[output path]:存储下载文件的路径,改为自己的实际路径。
不过需要注意,ascp 下载的数据有时会出现问题,进而导致下游分析如 trim_galore 在过滤 reads 时出错,以下是一些报错示例:
cutadapt: error: Line xxx in FASTQ file is expected to start with 'xxx', but found 'xxx'
可以通过 gunzip 命令检查是否是由于 fastq 文件存在问题:
1 | gunzip -t SRRxxx.fastq.gz |
以上情况可能并不是因为下载过程中的网络问题,而是 ascp 下载的文件本身存在问题,经实测某些文件下载不存在问题的话,不管下载多少次都不会出错。而某些文件如果下载后存在问题,那么不管下载多少次都会存在问题,这同时也体现了 prefetch 的特点 —— 慢但稳定。
参考资料
本文解决方案皆来自 sra-tools Github issue: