
JuseKit(三) —— 串联序列、根据id提取序列、批量修改文件尾缀
更新变动及进度
已有功能的相关教程请见:Juseの软件开发
更新日志
2023.06.21 完善了输出的 log 信息。
本次更新变动
- 对序列进行串联(支持 IQ-TREE 分区文件的生成)。
- 根据 id 提取序列。
- 批量修改文件的后缀(已经补充在第二篇的进阶应用中了)。
- 修复了部分 Bug。
目前的功能进度
- 提取最长转录本。(已实现)
- 根据 id 提取序列。(已实现)
- 对序列的 id 进行各种处理。(已实现)
- 串联序列并得到分区信息。(已实现)
- 批量改后缀。(已实现)
- 批量进行序列格式转换。(拟下一次更新)
- 批量 RBH 得到一对一直系同源基因。(拟废弃,因为 diamond 的 windows 部署有些麻烦)
- 批量提取 Orthofinder 的 orthogroup 对应的 CDS 序列。(拟下下次更新)
- 增加自动绘图模块(例如火山图、富集图等)。(考虑中,新的模块将会大幅增加软件大小,Juse 正在权衡利弊)
叠盾警告?:不保证这些功能和想法一定会实现,本软件解释权归属 Juse 所有,本软件能走多远具体得看 Juse 能坚持多久。
下载地址:https://github.com/JuseTiZ/JuseKit/releases
提取序列及串联序列
本文主要着重于这次更新新增的功能,其他模块请走这里。
根据 id 提取序列
可用到的场景应该比较少,但也是有些的,例如差异表达基因序列的提取等。
操作也很简单,如图:
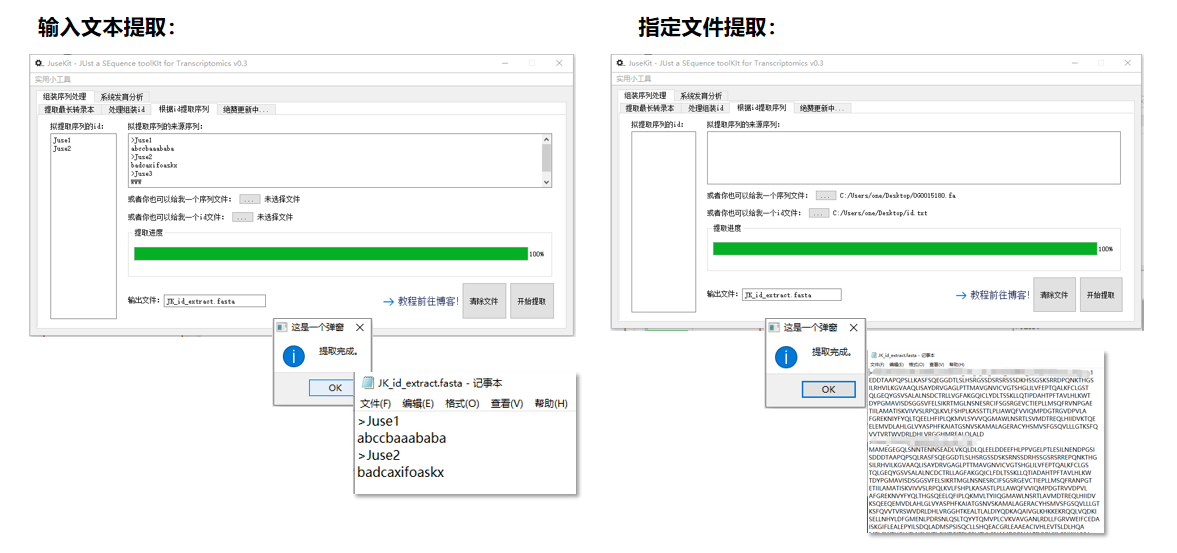
重点如下:
- 当输入文件且同时文本框中有输入时,文件更优先执行。
- 输入的 id 应为一行一个。
- 当使用文本框进行提取时,文本框的内容会保存在
.exe所在文件夹中,其中 id 保存在tmp_id.txt,fasta 保存在tmp_fasta.txt。输出的文件也在同一文件夹下。 - 当使用文件进行提取时,输出文件将和输入文件在同一路径。
串联序列
这一功能在 系统发育分析 中的第一个板块。
首先介绍一下各个地方的功能:
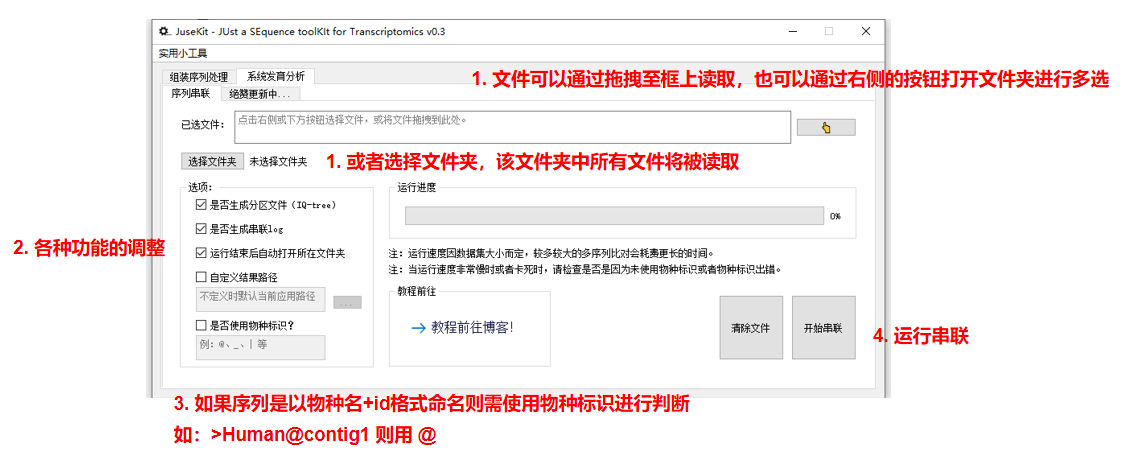
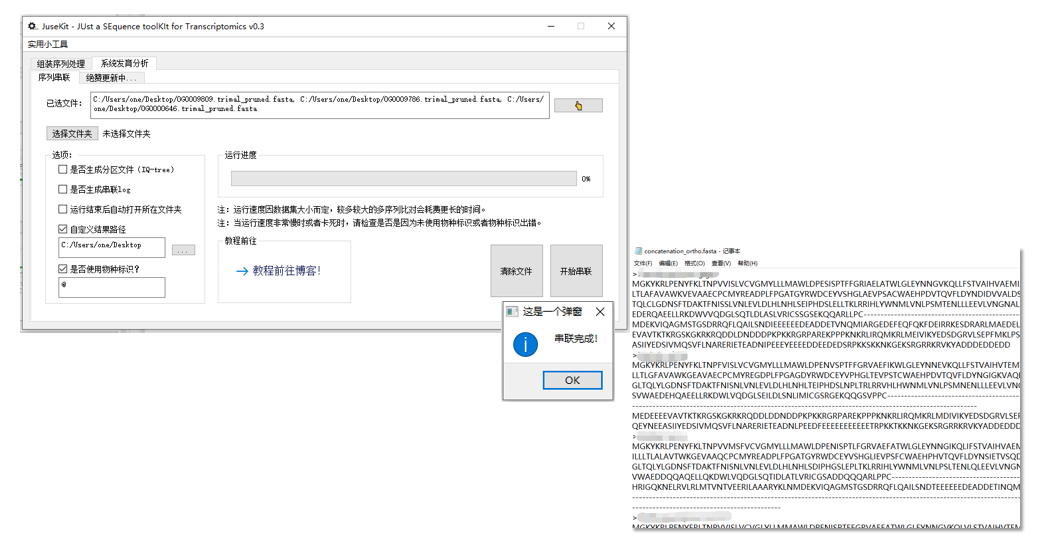
实例演示:
一些例外的情况:
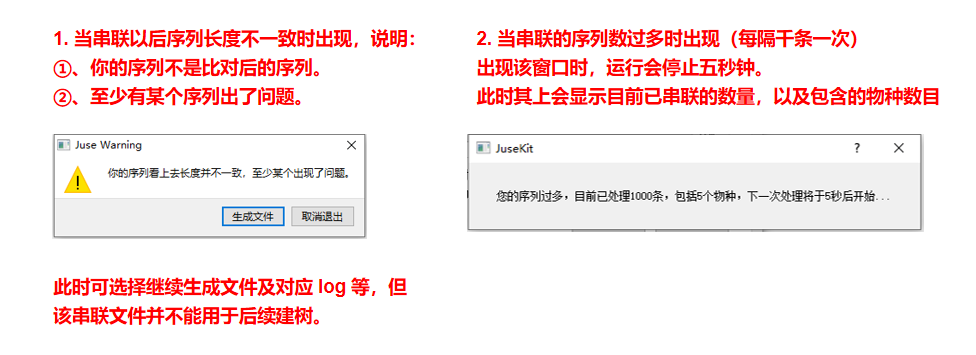
一般而言,串联需要用到的序列数量不会过多,所以运行速度会非常快,但如果数量过多,所需要的时间也会随之增加。
运行中卡死是比较正常的,但一般不会一直卡死,一直卡死说明可能未使用物种标识,导致识别到的物种数异常庞大,从而增加了内存需要。所以运行前请务必检查好这一点。
运行结束后,会在结果路径中产生以下文件:
concatenation_ortho.fasta串联结果。IQ_partition.txt适用于 IQ-Tree 分区模型建树的分区信息。sequence_con.log串联 log,展示了各物种信息(v0.6 新增了 gap 比例),其中最后一列应当全部为+。gene.log基因 log,展示了各个基因中所包含的物种(未出现的以-标识)及各物种的基因出现率。gene.log为 v0.62 新增,目的是为了更好地观察部分物种的高 gap 率是由于 missing gene 还是由于未修剪 gap。
后记
我会争取将这些功能慢慢完善,让它成为一个具有更广适用性的软件,希望能够帮助到某些盆友,当然我个人认为最大的可能是自娱自乐。
如果这个软件帮助到您了,您可以给它一个小小的 Star 聊表支持,或者在您汇报的时候引一下 https://github.com/JuseTiZ/JuseKit/ ,想必看着还是非常高端大气上档次的。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Juse's Blog!
相关推荐

评论