
JuseKit(二) —— 序列id简化、加前缀尾缀或转变为物种名
更新变动及进度
本次更新变动有:
- 对序列的 id 进行前缀或后缀(尾缀)添加。
- 对序列的 id 进行简化。
- 对序列的 id 进行转换(变为物种名)。
部分功能的 Python 代码实现:比较转录组分析(三)—— 组装的质量检测与去冗余
更新变动
2023.04.13 新增了批量替换尾缀的功能,在进阶应用里进行了补充。
2023.04.24 处理组装 id 中的 删除原有文件 功能在什么时候都能使用了。
目前的功能进度
- 提取最长转录本。(已实现)
- 根据 id 提取序列。(拟下一次更新)
- 对序列的 id 进行各种处理。(已实现)
- 串联序列并得到分区信息。(拟下一次更新)
- 批量 RBH 得到一对一直系同源基因。
新的想法
- 批量提取 Orthofinder 的 orthogroup 对应的 CDS 序列。
- 批量进行序列格式转换。
- 批量改后缀。(拟下一次更新)
叠盾警告?:不保证这些功能和想法一定会实现,本软件解释权归属 Juse 所有,本软件能走多远具体得看 Juse 能坚持多久。
下载地址:https://github.com/JuseTiZ/JuseKit/releases
ID 处理
基本应用
本文主要着重于序列 id 的处理部分,其他模块请走这里。
这个模块的样子:
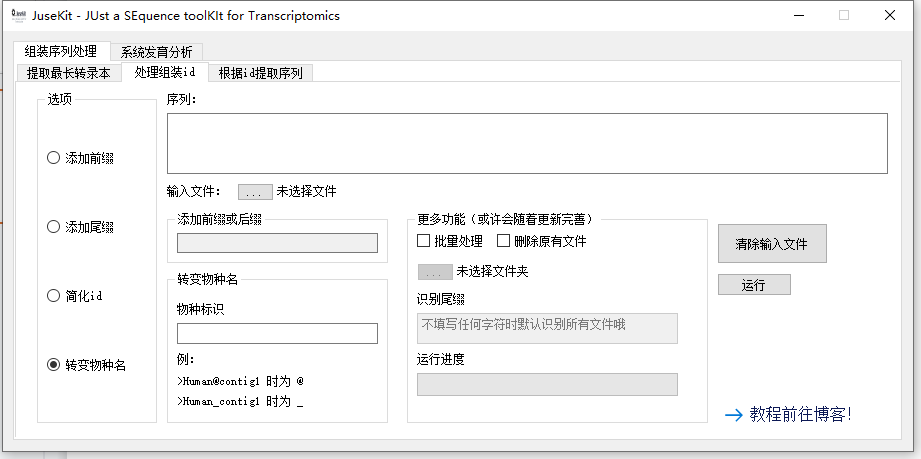
选项卡内是所有的功能,其余部分则为对应需要填写的信息以及批量处理等功能。
当你是在序列框中输入序列时,处理的序列会保留在 JuseKit.exe 所在文件夹中并被命名为 JuseKit.fa,生成的文件将是 JuseKit.mod.fa。当选择的选项不同时,所生成的文件尾缀也不同,前缀、尾缀、简化 id 以及转变物种名分别代表 pre、suf、sim 和 spe。
当选择文件进行处理时,处理的序列会保留在所选文件的文件夹中并被命名为 所选文件名.mod.fa,尾缀规则同上。
当选择前缀或后缀时,运行方式为:
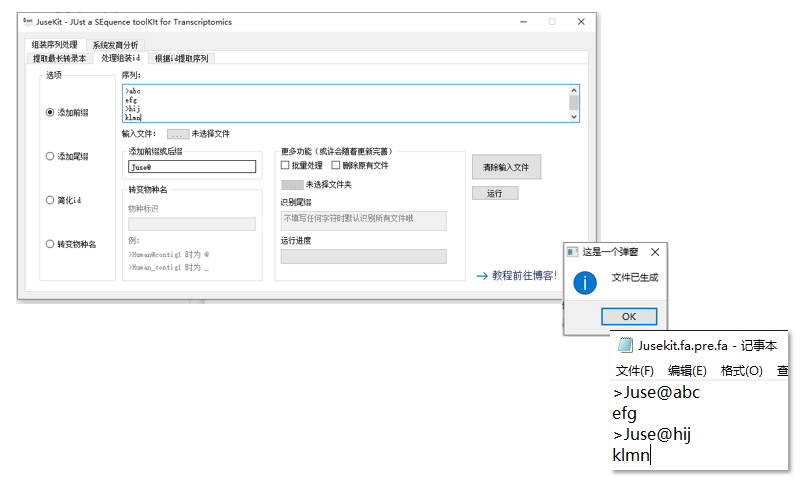
当选择物种标识时,运行方式为(以上面生成文件为例):
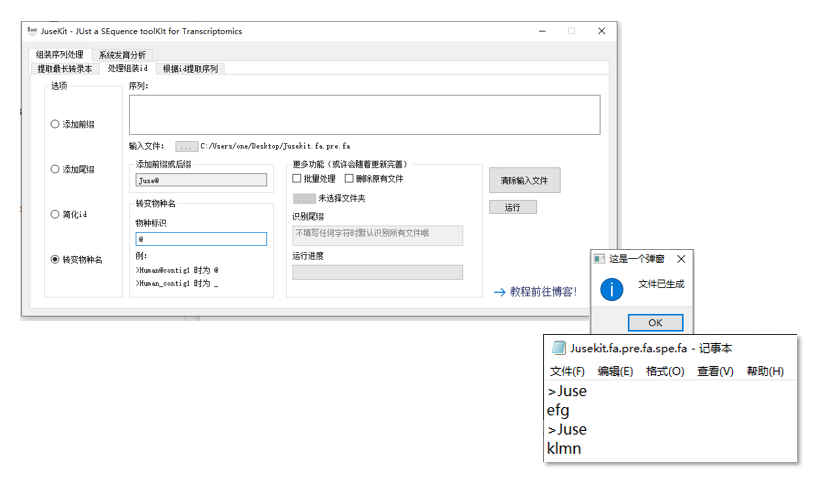
可以根据自己的序列名称自行定义物种标识,例如 _ 或 | 等。
当选择简化 id 时,不需要填写任何东西,直接运行即可。
进阶应用
批量处理是什么意思?它有什么用?
批量处理即将目标文件夹中所有的序列进行相同处理,从而便利于大规模的数据操作。
将选项与删除原有文件绑定,即删除原有文件并不会在其他功能中发挥作用。
2023.04.24 新版本中修复了部分闪退 bug,并且将删除原有文件选项与批量处理之间的绑定关系取消了。
叠盾警告?:在未存有备份文件的情况下请勿使用 删除原有文件 选项,否则造成的问题 Juse 概不负责。
这个选项很大程度上是为了 转变物种名 选项服务的,以下将以实际例子进行演示:
假设我有很多个多序列比对文件,其中每条序列可能来自于不同的物种,并且这些序列 id 的开头已经有 >物种名@ 标识。
1 | >Human@Contig1 |
这时就可以使用批量处理,将这些序列的 id 转变成对应的物种名,方便之后的一系列分析。
操作示例:
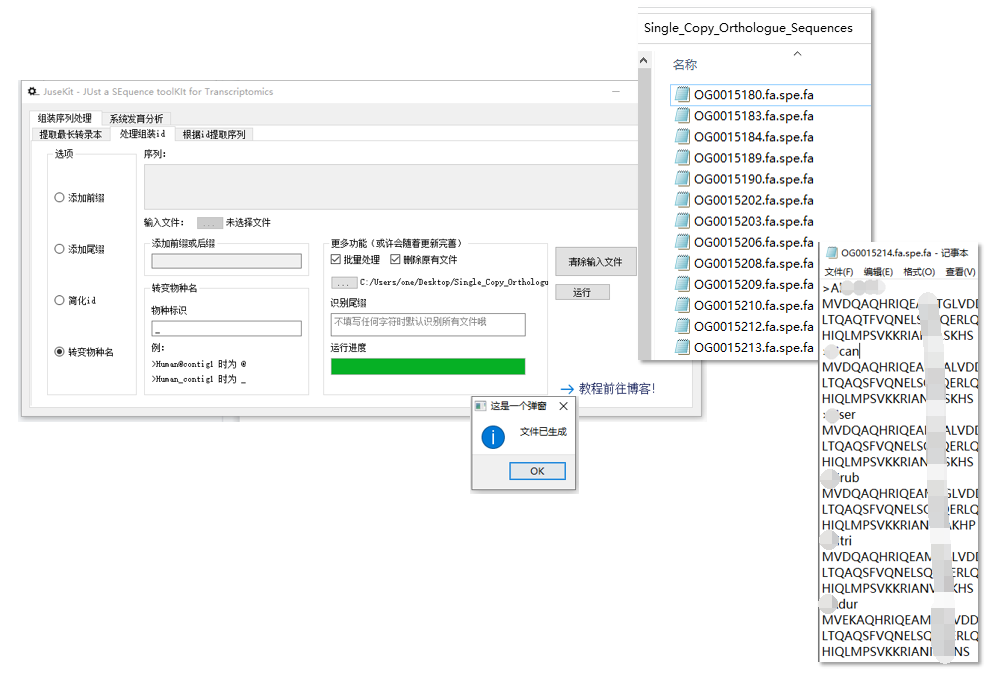
软件的进程会在批量处理工具卡下方的进度条显示,如果只想对特定文件处理,请在工具卡中指定文件尾缀,否则将对文件夹中的所有文件进行。
v0.3 更新
你的尾缀太憨憨了,我想要原来的样子!
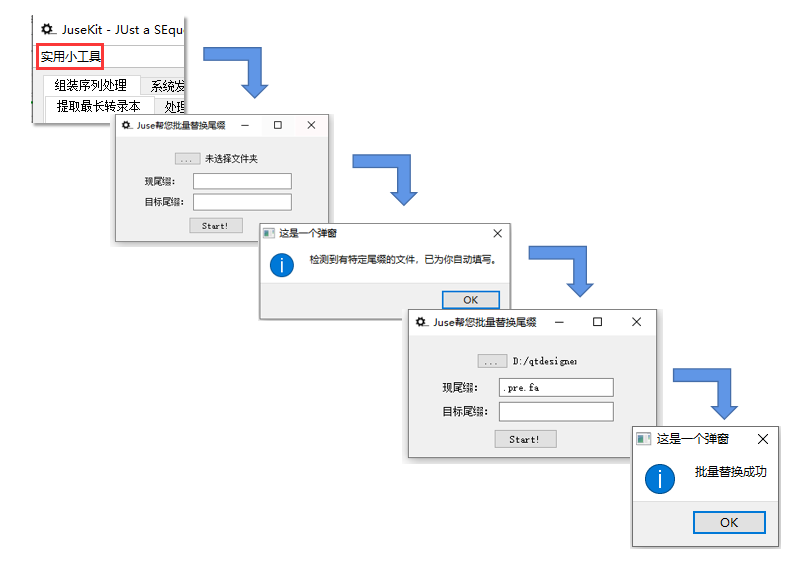
v0.3 新增了批量替换尾缀的功能,在使用本文中的批量处理功能后,可以使用左上方工具栏中的第一个功能进行使用。
打开文件夹后,它会自动识别已有文件的尾缀并进行填充,直接运行就可以让它们变回去了。
后记
我会争取将这些功能慢慢完善,让它成为一个具有更广适用性的软件,希望能够帮助到某些盆友,当然我个人认为最大的可能是自娱自乐。
如果这个软件帮助到您了,您可以给它一个小小的 Star 聊表支持,或者在您汇报的时候引一下 https://github.com/JuseTiZ/JuseKit/ ,想必看着还是非常高端大气上档次的。
